In 2016, this paper, written by Google Deepmind researchers, opened the era of one-shot learning in deep learning. This paper is logically well organized and written and contains the writer’s deep thought on its logic. We will start to review this paper and the idea behind it.
Before 2016, it was astonishing that deep learning could perform any vision task with high accuracy, which we could not imagine when we were using hand-crafted methods. However, there was one crucial drawback; due to a hugely parametric nature of the deep neural network, the model requires tones of data for training. To this end, the author starts the background of their method by introducing this drawback of the deep neural network.
Obviously, the author must be inspired by non-parametric methods. By incorporating the merits of non-parametric and parametric methods, the author might have thought to make deep learning more like human recognition. So the author successfully invented a new learning meta, Matching Networks for one-shot learning. The idea behind this method is not simple and contains the author’s deep-diving thoughts into this idea.

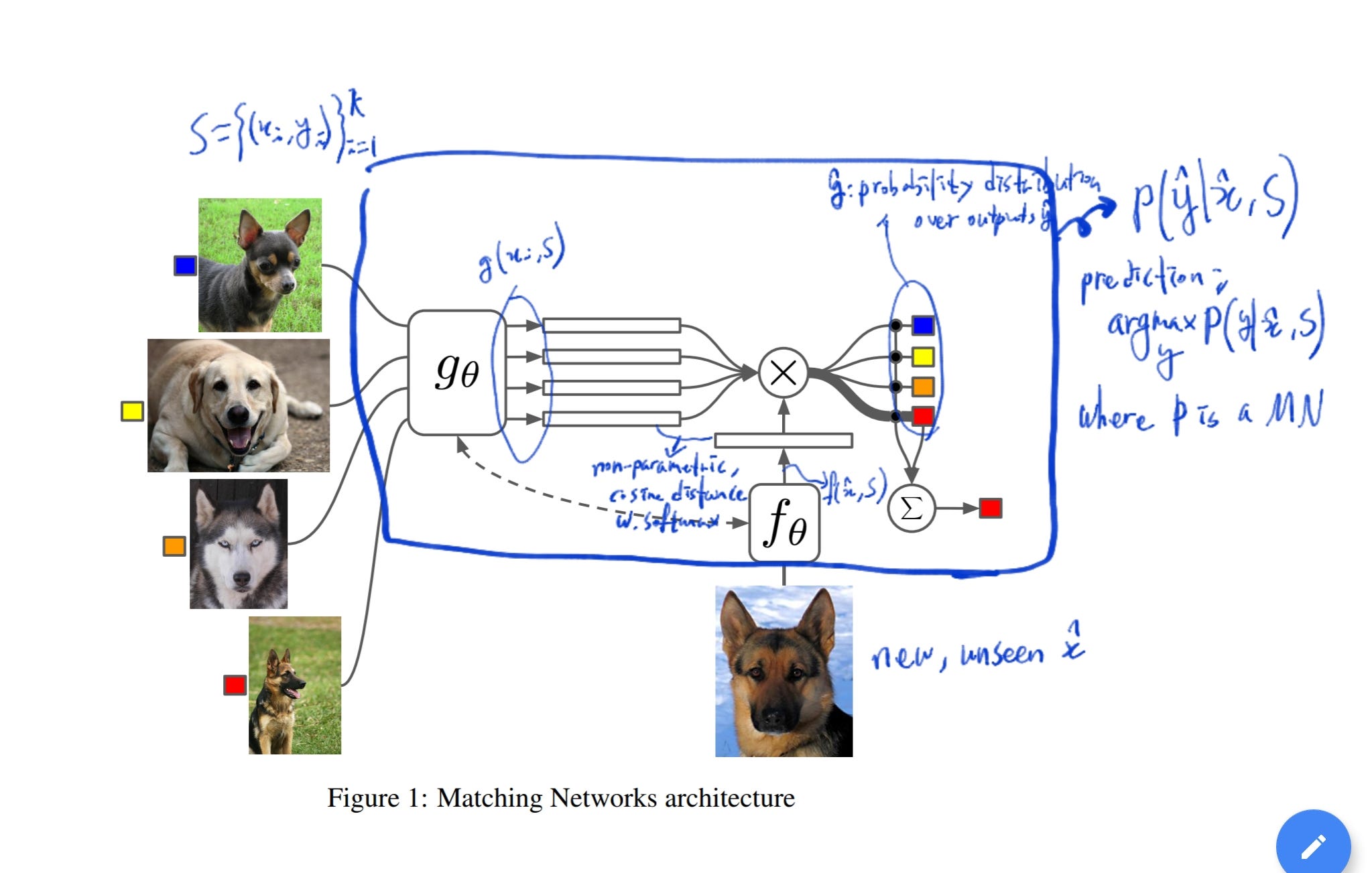
The author starts his idea, where he defines the model for one-shot learning. Given a support set S, the model defines a function cs (or classifier) for each S, i.e., a mapping S-> cs(.).
The author describes his idea on model architecture through one main section and two subsections; main section for describing model definition on S and non-parametric kernel a(x, xi), and subsections for describing the attention kernel a(x, xi) and for full context embedding on the view of using LSTM and set S.
Matching Network problem and solution space.
Mapping S ->cs(x) is defined as P(y|x, S), which the author calls Matching Network. Matching Network is a parametric nature of the proposed method.
When finding the answer, the author try to solve
y = Sum( a(x, xi)yi ) …….. (1)
where a is an attention mechanism, the kernel on XxX. This mechanism is a similar method to KDE or kNN, and below is why.
If the attention mechanism is a kernel on XxX, then (1) is similar to KDE.Using attention mechanism a, when dist(x, xi) is measured by using some distance metric, and b number of outputs are 0, then finding the argmax_y is similar to ‘k-b’-nearest neighbor searching.
Moreover, the author introduces another view.
In another aspect, the operation can be interpreted as picking up an xi, yi pair by searching appropriate pair in the memory given an input x.
The above interpretations are a clear explanation that the author successfully integrated non-parametric methods and his parametric network architecture P.
The attention kernel
Here is a core part of the non-parametric method in this paper. Once the functions f and g, modeled as an LSTM architecture, gets the output features f(x) and g(xi), these features, as described above section, can be used to calculate distance and therefore perform a k-nearest neighbor search. More specifically, the author used cosine distance c, followed by softmax operation, thereby fining apparent answer y.
Full context embeddings
It seems superficially enough so far, but the author criticized himself that g(xi) is hastily assumed that xi is independent over others in S. So the author suggests g(xi, S) instead. It is why the author calls full context embedding. It makes sense that xi should be embedded upon the overall context of S. We will see if it is an effective solution when we check the result section.
In a similar way, the author suggests f(x, S) instead of f(x).
The model is pulled from LSTM methods in previous research, where the author easily exploit the idea of memory storage for the support set S. This is how the author supports his idea on using g(x, S) and f(x, S) instead of plain g(x) and f(x).
Training strategy
So far, the author has revealed his idea and overall architecture of Matching Networks. Now the author explains how to train these networks. He wanted to expand the possible set of L by random sampling from T. Then from set L, S and B are sampled to be a support set and batch(target) set.
Once again, the author emphasizes that this method does not need any fine-tune, i.e., one-shot learning method. It is because, after initial training, Matching networks only work in a non-parametric way, using the S and x as input for the nearest neighbor idea.
Until now, we have investigated the idea of this paper. The author suggests a few solutions for his hypotheses. If we want to check its effectiveness, we can see the Experiments section. Although it seems not a perfect solution, the idea works very well. One thing we should think more is that this method did not perform well in one case in Table 3. The author tries to explain why, but questions remain.
댓글 없음:
댓글 쓰기